





Let’s be honest: we’re all a little tired of hearing about the latest MT engine that produces “almost human-like” machine translations or “no longer requires human review.” Yes, MT engines are evolving. The Google-DeepL duopoly has been broken, and new language models are achieving impressive results on benchmarks. But why are we still convinced that strong benchmarks won’t help us? How can we integrate МТ into the translation process so that it actually helps instead of getting in the way? We discussed these questions with Igor Kamerzan, a localization engineer at Inlingo.
Good benchmarks are no panacea
A benchmark is a specially curated and annotated dataset that is used to objectively compare and evaluate the quality of different machine learning models.
Benchmarks act as a common standard, allowing researchers and developers to determine which model is faster, more accurate, or more efficient when using the same data.
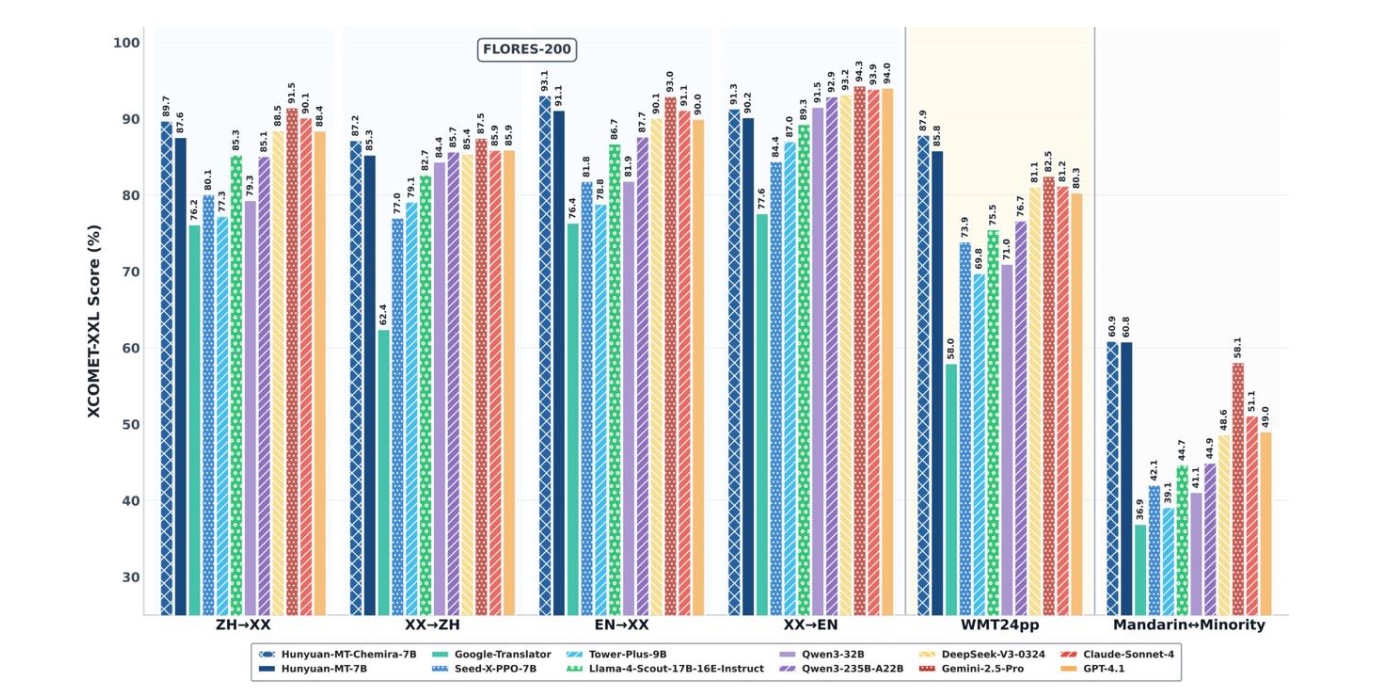
MT engine results on WMT-2025. Source
Here are the MT engine results on the WMT-2025, which is considered the gold standard for evaluating translation quality. At first glance, the numbers are impressive. But what’s the catch?
The problem with all of these engines is that most of the results come from the so-called “vanilla” datasets. In real life, we rarely translate Wikipedia articles. We translate video game texts in various genres with hundreds of distinct words and unique characters—not D’Artagnan or Captain Nemo, but original heroes and creatures. However, that’s not the biggest challenge.
The core problem with MT
Here’s the real pain point: MT engines treat every new line as a blank slate. When you send them line by line, they have no memory of what came before. For an MT engine, each line exists separately from all the previous lines—and from the project as a whole. That’s why you end up with the same name translated in two different ways on neighboring lines. Another example: the MT engine correctly parsed a question posed to a character who slew a dinosaur but failed to recognize that the next line was that same character’s response.
A professional linguist working on a project takes all these issues into account. On top of that, CAT tools provide support through Translation Memory (TM) and a Terminology Base (TB), which are key resources for any serious translation project. They store translations of strings already approved by the translator, as well as words marked as terms. These resources help linguists keep a clear head and quickly recall appropriate translations.
RAG MT to the rescue
Some MT systems allow you to add a translation memory and a glossary to the prompt—and then the neural network should produce a translation that takes the TM and TB into account. This feature is sometimes referred to as “adaptive translation,” “AI translation,” or even “never-before-seen technology,” but it is essentially based on RAG technology. RAG enables “adaptive” machine translation and is ideal for context-sensitive translation tasks.
Before generating an answer, the RAG model first searches for relevant information in the provided knowledge bases (TM, TB). Then, it augments its original prompt with the context clues it found and generates the translation.
In this way, RAG acts as “artificial memory” for the MT engine. Rather than guessing whether to translate a name as “Karl” or “Karel,” the model queries the terminology base and translation memory, finds the correct option, and uses it to ensure consistency. This dramatically improves translation consistency, especially in large, complex projects, where every detail of the story matters.
Why we need ad hoc translation memory
Let’s say we’ve taken translation memory into account. It would also be useful if the engine could remember what it just translated, even if that information hasn’t yet been added to the TM by a translator or reviewer. For this, there should be a kind of ad hoc translation memory. Its confidence level may be lower, but it can still provide the engine with clues informing the correct translation.
This would help the engine still remember what it has just produced while continuing the translation. Of course, you could translate sentences one by one and manually add the results to the TM—but who wants that kind of monkey work?
Maximizing the power of the prompt
So, we have TM, TB, and ad hoc TM. What’s next? I think everyone would agree with the saying, “You can never have too much context.” Beyond previously translated sentences, the context needed for translation can come from anywhere: string IDs, translations into other languages, dev notes, neighboring columns in a spreadsheet, or even direct instructions from developers. Very often, it’s from these sources that a translator learns the most important details: who is speaking to whom, the purpose of the string (e.g., a quest name or the quest text itself), length limits, what the developers want to see, and which entries from the TM should be used as references. Of course, there are also the style guides and the wikis. To ensure that AI has the same conditions as a human linguist, it is vital to provide it with all this information.
Ultimately, the main task is to build the right prompt. The final prompt will be quite large, and the model’s attention may become scattered. There’s no need to worry, though. Modern engines handle these instructions carefully, and the cost of tokens isn’t that high. In fact, the amount of context added to the prompt should be many times larger than the text being translated. For instance, one of our projects had about 90,000 words to translate, while the token usage, including context, ended up reaching several million.
At this point, it doesn’t really matter which LLM you use; just pick one of the top models in the chart above that fits your budget. There are open-source options, too. When used with the right approach, any LLM released in 2024–25 will deliver far better results for your project than it would in its raw form. This process gives AI access to as much information as a linguist would have during translation.
Quiz your MT provider
Ask whether their LSP/TMS/CAT can actually support this kind of MT workflow, or if they’re simply promising that everything will work perfectly “out of the box” with no “human intervention” required. Here’s a short checklist:
- What engine/model is used for translation, and why was it chosen?
- What objective quality metrics has it shown on benchmarks or on your internal test dataset?
- Does it take into account the context of individual lines already stored in the translation memory?
- Does it use ad hoc translation memory, which is information that the engine has translated in the same task but that hasn’t yet been added to the TM?
- Does your system support prompt customization that would allow us to add all the necessary information for each string?
- Does the translation process include technical fields: string IDs, developer comments, tags, and length limits? Does it also use the file name and path as a source of context?
- How does your system determine the confidence level (match score) of suggestions from the TM/ad hoc memory?
- Does your system take into account translations already completed into other languages for the same project, if available?
- Can you attach the set of entire files with additional context (character bibles, specifications, style guides) to be used in search queries?
At Inlingo, we’re ready to answer all these questions and offer a tailored workflow. On top of that, we can fine-tune an MT engine with your own texts. This would ensure the AI is prepared from the start to deliver translations that reflect their specifics and terminology. Combined with the ability to supply the model with the right context, your MT engine can become a truly powerful tool.




{kind=link}